0 Inhaltsverzeichnis §
- Grundlagen
- OLTP/OLAP
- ACID
- DB/DBMS/DBS
- DDL/DML/DCL
- ER-Modelle
- Relationenmodell
- ERD -> Relationenschema
- Generalisierung Methoden
- Join (outer/semi/…)
- Division
- Anfrageoptimierung
- Funktionale Abhängigkeit
- Superschlüssel, Schlüsselkandidat
- 1NF, 2NF, 3NF Überführung
- SQL
- Datentypen
- CREATE , ALTER, DROP TABLE
- INSERT, UPDATE, DELETE, SELECT
- UNION, INTERSECT, EXCEPT, CASE WHEN
- Mehrnutzerbetrieb
- Views
- Users, Roles, Permissions
- Mehrbenutzeranomalien
- SX-Matrix
- Isolation levels
- Journaling
- Anwendungsentwicklung
- JDBC Connection, (Prepared)Statement, ResultSet, Metadata
- PL/pgSQL Procedures, Functions, Trigger
- Clustered Index, B-Baum, B+-Baum
- Join-Algorithmen
1 Grundlagen §
| OLTP | OLAP |
|---|
| OnLine Transaction Processing | OnLine Analytical Processing |
| Viele schnelle Anfragen | Komplexe Anfragen |
| Database | Data Warehouse |
- Atomicity (Alles oder nichts)
- Consistency (Nur erlaubte Zustände)
- Isolation (Kein gleichzeitiger Zugriff)
- Durability (Systemcrash-Schutz)
| DB | DBMS | DBS |
|---|
| Datenbank | Datenbank-Managementsystem | Datenbanksystem |
| Daten | PostgreSQL | DB + DBMS |
| DDL | DML | DCL |
|---|
| Data Definition Language | Data Manipulation Language | Data Control Language |
| Metadaten/Datenbankschema | CRUD | Benutzerverwaltung |
2 ER-Modelle §
- Sind alle Kardinalitäten an Beziehungen?
- Kardinalitäten richtig herum?
- Gibt es überflüssige Entitätstypen?
- Hat jeder Entitätstyp einen Primärschlüssel?
- Müssen manche Entitätstypen schwach sein?
- Ist die entsprechende Beziehung doppelt umrahmt?
- Sind erweiternde Primärschlüssel unterstrichelt?
- Sind Generalisierungen korrekt modelliert?
3 Relationenmodelle §
| ERD | Relationenschema |
|---|
| Entität | Tabelle |
| Attribut | Spalte |
| Subattribut | Einzelne Spalten |
| Mehrwertiges Attribut | 1:N Beziehung |
| Beziehungen | Fremdschlüssel |
| Schwache Entität | Zusammengesetzter PK |
| Ternäre Beziehung | wie N:M Beziehungen |
| Generalisierung | siehe unten |
| Generalisierungsmethode | Erklärung |
|---|
| Volle Redundanz | Jede Entität wird zu einer Tabelle mit allen Spalten, führt zu Redundanz |
| Hausklassenmodell | Wie volle Redundanz, aber es wird nur in eine Tabelle eingefügt |
| Vertikale Partitionierung | Bei Subentitäten nur spezielle Spalten übernehmen |
| Hierarchierelation | Nur eine Tabelle mit allen Spalten, + type tag |
Joins §

| Typ | Erklärung |
|---|
| Equi-Join | Nur = |
| Theta-Join | < ≤ = = ≥ > |
| Natural Join | Equi-Join mit gleich heißenden Attributen |
| Semi-Join | R⋉S bzw. R⋊S: πR.∗ bzw. πS.∗ |
Division §
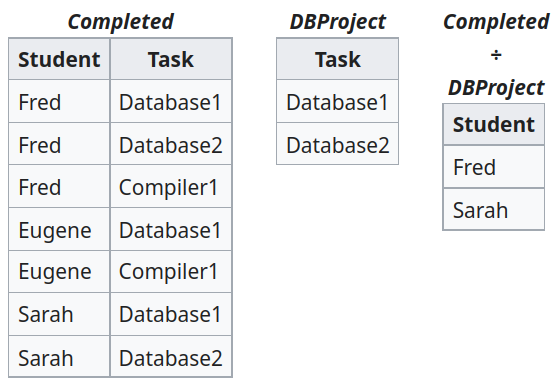
(R×S)÷S=R
Heuristiken §
- Selektion, Projektion früh und zusammengefasst
- Kleine Zwischenergebnisse
- Selektion statt Mengenoperation
Kardinalitätsschätzung §
- ∣σR.a=x(R)∣=∣R.a∣∣R∣
- sfP=∣R∣∣σPR∣
- ∣R×S∣=∣R∣⋅∣S∣
- 0≤∣R⋈S∣≤∣R∣⋅∣S∣
- ∣R⋈R.a=S.aS∣=∣R∣ bzw. ∣S∣
Abhängigkeit §
A⇒B falls A→B und ∄A′⊊A:A′→B
Schlüssel §
- Superschlüssel: A→R
- Schlüsselkandidat: A⇒R
| NF | Eigenschaften | Überführung |
|---|
| 1NF | Attribute sind atomar | Attribute flachklopfen |
| 2NF | nicht-Schlüsselattribute hängen voll vom ganzen Schlüssel ab | Zerlegung in Tabellen |
| 3NF | keine transitive Abhängigkeiten | A→B→C wird zu A→B und B→C |
4 SQL §
DOUBLE/REAL: FließkommazahlDATE: Jahr-Monat-TagDECIMAL(p, s): p Stellen, davon s Nachkommastellen
FOREIGN KEY (a, b) REFERENCES table(c, d) ON {DELETE|UPDATE} {RESTRICT|NO ACTION|SET NULL|SET DEFAULT|CASCADE}
CREATE TABLE kunden (
kundennummer SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(500) CHECK (email LIKE '%@%') UNIQUE,
passwort CHAR(32),
land VARCHAR(100) DEFAULT 'Deutschland',
geworben_von INT REFERENCES kunden(kundennummer)
ON DELETE SET NULL ON UPDATE CASCADE
);
CREATE TABLE privatkunden (LIKE kunden); -- Übernimmt Attribute
CREATE TABLE privatkunden2 AS SELECT * FROM kunden -- Übernimmt Zeilen
ALTER TABLE kunden {ADD|DROP|RENAME} COLUMN my_col [INT|...];
INSERT INTO kunden(kundennummer, name) VALUES (default, 'jeff');
UPDATE kunden SET name='jeff' WHERE kundennummer=3;
DELETE FROM kunden WHERE ...;
TRUNCATE TABLE kunden;
SELECT DISTINCT H.land, COUNT(*) AS anzahl, AVG(P.preis) AS avg_preis
FROM hersteller H JOIN produkte P ON H.firma = P.hersteller
WHERE P.preis > 3
GROUP BY h.land
HAVING COUNT(*) < 5
ORDER BY COUNT(*);
WITH ... AS (SELECT ...) SELECT ...;
SELECT ... UNION/INTERSECT/EXCEPT [ALL] SELECT ...;
SELECT CASE preis WHEN 0 THEN 'kostenlos' ELSE preis END FROM ...;
5 Mehrbenutzerbetrieb §
CREATE [MATERIALIZED] VIEW my_view AS SELECT ... [WITH CHECK OPTION];
REFRESH MATERIALIZED VIEW my_mat_view;
CREATE USER noah WITH PASSWORD 'abc';
CREATE ROLE cool;
GRANT cool TO noah;
GRANT {PERM} ON {ALL TABLES|...} [IN SCHEMA my_schema] TO {USER} [WITH GRANT OPTION];
REVOKE {PERM} FROM {USER} [RESTRICT|CASCADE];
- Dirty Read: Unterschiedliche Werte
- Lost Update: Parallele Änderung, 1 geht verloren
- Non-repeatable Read: Untersch. SELECT-Erg. in einer TA
- Phantomproblem: Anzahl Zeilen inkonsistent
| Isolation level | Lost Update | Dirty Read | Nonrepeatable read | Phantom read | Serialization Anomaly |
|---|
| Read uncommitted | | ✅ | ✅ | ✅ | ✅ |
| Read committed | | | ✅ | ✅ | ✅ |
| Repeatable read | | | | ✅ (❎PG) | ✅ |
| Serializable | | | | | |
| LSN | TA | PageID | Undo | Redo | PrevLSN |
|---|
| Log-Sequenz-Nr | Transaktion | Page auf Festplatte | Verlierer | Gewinner | Gleiche TA, vorherige Aktion |
6 Anwendungsentwicklung §
JDBC §
// Summary:
"jdbc://postgresql://host/db?currentSchema=schema";
DriverManager.getConnection(url, user, pass);
conn.prepareStatement("...").setString(1, "...");
st.executeQuery().next().getString(1);
rs.getMetaData().getColumnCount();
String url = "jdbc://postgresql://host/db?currentSchema=schema"
Connection conn = DriverManager.getConnection(url, "user", "password");
conn.close();
Statement st = conn.createStatement();
PreparedStatement pst = conn.prepareStatement("SELECT * FROM t WHERE id = ?");
pst.setString(1, "id");
ResultSet rs = st.executeQuery();
while (rs.next()) {
String col1 = rs.getString(1);
int my_col = rs.getInt("my_col");
}
DatabaseMetaData data = conn.getMetaData();
ResultSet rs = data.getTables("catalog", "schema", "table");
ResultSetMetaData data = rs.getMetaData();
data.getColumnCount();
data.getColumnName(0);
data.getColumnTypeName(0);
PL/pgSQL §
IF ... THEN ... ELSE ... END IF;
WHILE ... LOOP ... END LOOP;
LOOP ... EXIT WHEN ...; END LOOP;
FOR ... IN ... LOOP ... END LOOP;
CREATE OR REPLACE {FUNCTION|PROCEDURE} my_fun(INT) RETURNS INT AS
$$ DECLARE
-- variables
BEGIN
-- code
RETURN $1;
END $$ LANGUAGE plpgsql;
B-Baum §
- Zwischen 0 und 2k+1 Kindknoten
- Zwischen k und 2k Einträge pro Knoten
B+-Baum §
- Zwischen k* und 2k* Einträge pro Blatt
- Suche: < links, ≥ rechts
- Einfügen: (1) Suchen (2) mittleren Knoten kopieren (3) linke und rechte Knoten splitten (4) bei Vater verschieben
- Löschen: (1) Suchen (2a) Aus Nachbarblatt ausgleichen und Wegweiser anpassen (2b) Mit Nachbarblatt mischen und Wegweiser entfernen
CREATE INDEX my_table_pkey ON my_table(pkey_col);
CREATE INDEX ON meine_tabelle(a, b, c);
VACUUM my_table;
Join-Algorithmen §
Nested-Loop-Join
for each row r in R:
for each row s in S:
if r.sId == s.id:
emit(r, s)
Sort-Merge-Join
- Nach Join-spalte sortieren
- Von oben nach unten Join-Partner suchen
Hash-Join
hash_table = []
for each row r in R:
hash_table.put(hash(r.sId)), r)
for each row s in S:
r = hash_table.get(hash(s.id))
emit(r, s)
Index-Join
for each row r in R:
s = s_id_index.get(r.sId) # e.g. using B+-Tree search
emit(r, s)